
27
Jun
ARCOS Symposium 2024
Go to eventabout ARCOS Symposium 2024

A quick search online for Tolstoy’s War and Peace throws up 113 editions – the clothbound edition translated to Portuguese by Rubens Figueiredo and published in 2 volumes by Cosac & Naify in 2011; the ‘authoritative modern abridgement’ by Edmund Fuller; the ‘inner sanctum edition’ by Simon & Schuster 1955; the Amazon Classics Kindle edition 2019…illustrated, annotated, audiobook, ebook, paperback, cassette, CD…it goes on.
Now, a framework used by librarians for cataloguing books is shedding light on how researchers can precisely identify the digital dataset that underpins their work – a critical element of making sure the research is reproducible.
Only last year, we saw eminent journals The Lancet and The New England Journal of Medicine retract 2 COVID-related papers when the provenance of the data, and even its existence, were found to be in question; the authors, it seems, had relied on summary data supplied by a company.
Many publishers are demanding to know explicitly what data the researchers used, says CSIRO Principal Research Scientist Jens Klump, a passionate advocate for data versioning and co-author (with Lesley Wyborn and Mingfang Wu from ARDC, and others) of the paper, “Versioning data is about more than revisions: A conceptual framework and proposed principles,” published in Data Science Journal in March 2021.
With more and more data being downloaded from web servers, and large datasets being broken into subsets, the versioning problem is now acute, according to the authors.
Imagine an ecological monitoring time series dataset that is updated in real time through sensors. Or a Twitter subset being used to analyse public sentiment and predict the outcome of an election.
“When researchers get a copy of the data, often they don’t know what they’re getting, who created it and what its licence is,” says Klump.
“Data citation was initially ‘nice to do’ – now it’s a ‘must have’ for reproducibility and for acknowledging the identity of contributors, including funders.”
We’ve had the means to precisely identify datasets for about a decade – the persistent identifier. Yet, across the global research community, there is no agreed way of versioning data.
Lesley Wyborn co-chairs the international Research Data Alliance (RDA) working group for data versioning, which, since 2016, has been nutting out the problems this causes and searching for a solution – a quest of such complexity that even the W3C (World Wide Web Consortium) temporarily shied away from it, she says.
The group spent 2 years gathering 39 use cases from 33 organisations, among them Australia’s IMOS, QCIF, Geoscience Australia, NCI, TERN, CSIRO and the Bureau of Meteorology. The greatest confusion from the use cases was about terminology – the terms version, revision and release were often used interchangeably, despite meaning different things.
Several questions emerged from the analysis of the use cases:
Jens Klump looked to software versioning practices, which are well established, but found them lacking in their support of reproducibility.
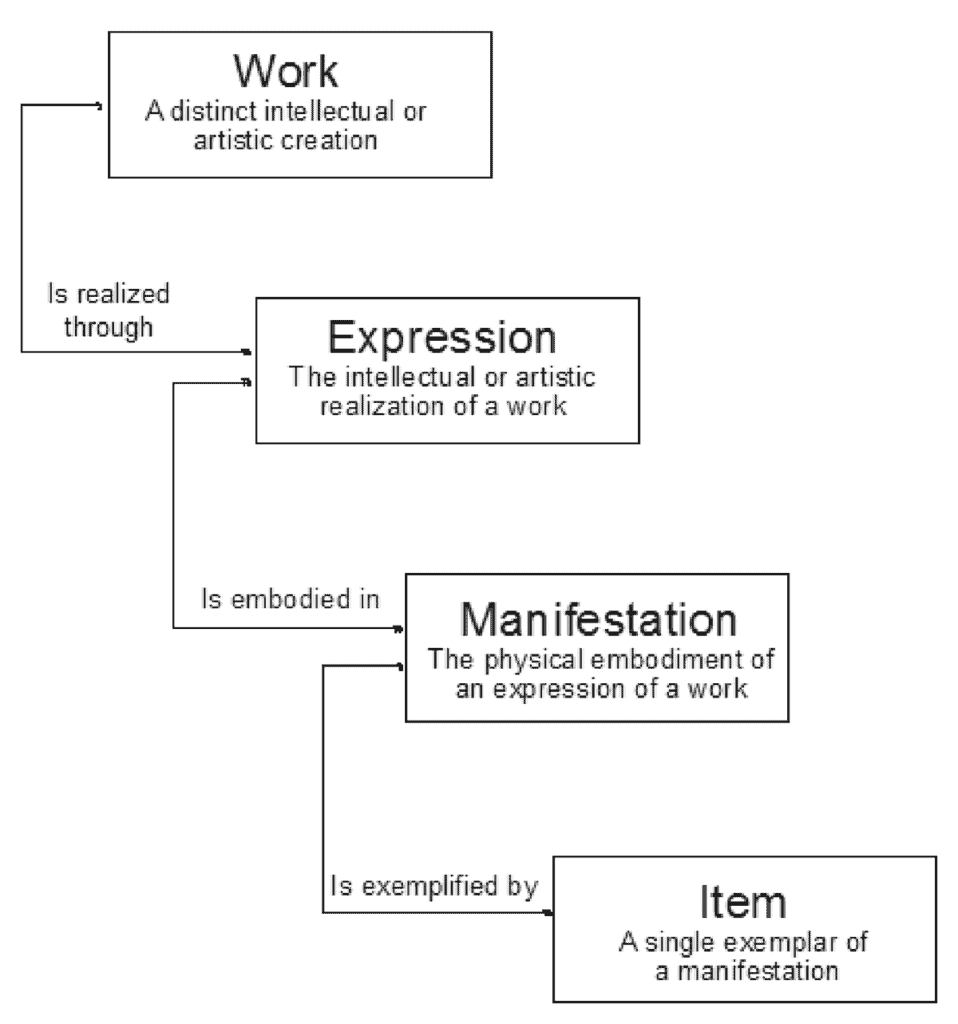
It was the internationally agreed conceptual framework used by libraries – the Functional Requirements for Bibliographic Records, or FRBR – that proved most useful.
“Even in the pre-digital library, to catalogue a book, the librarian had to know the version, language, translation – we saw a parallel in the digital age,” explains Klump.
“What I particularly like about FRBR is the distinction between the creative/intellectual work and its physical embodiment.”
The culmination of the group’s work, documented in the paper, is a framework for data versioning based on FRBR concepts and comprising 6 guiding principles:
Note, the principles are summarised here. Please read the published paper for a full description.
The need for data versioning extends beyond research reproducibility to attribution, with journal publishers requiring that appropriate credit be given to whoever collected, curated and/or preserved the data in a publication (and earlier versions it may have been derived from).
“When we write a paper, we cite the ideas of other people. We do that, but not for data,” says Klump.
What research funders are now realising, he adds, is that they are not getting recognition for data they originally funded, and as a result cannot see the full impact of their investment.
“Increasingly we are talking about national collections, or satellite data where there is a major mission to collect it. People are taking subsets of data and the funders are not getting any credit. With web services, it’s rife – you select all the data that meets your criteria, download it, make a subset. If you did that in a paper, it would be fraud,” says Klump.
“And the people who paid for the original satellite mission can’t trace the entire set of research papers that came out of their original mission, except as a manual exercise.”
For the 26 projects funded under the ARDC Platforms program, the data versioning principles are welcome and timely, says ARDC Platforms Program Manager Kerry Levett:
“These [new] platforms are providing access to very large datasets. They’re all in the architecture phase at the moment, so they can use the principles and perhaps even be test cases,” she says.
“We’re looking to encourage best practices in setting up the infrastructure to give appropriate recognition and attribution and to make it easier for researchers to cite.”
The 6 principles represent a first considerable step in a complex frontier area of scientific method in the information age.
How to apply the 6 principles to questions of attribution, authority and ethics arising from data publication and sharing is still on the agenda for RDA.
But first they plan to raise awareness of the principles, and develop them into actionable recommendations and best practice guidelines. An RDA interest group has been revived to take this forward.
The saga continues to unfold in this long story, so stay tuned for Season 2.
Read our guide to data versioning, or learn more about the ARDC persistent identifier services for datasets.
The ARDC is funded through the National Collaborative Research Infrastructure Strategy (NCRIS) to support national digital research infrastructure for Australian researchers.


