
Thematic research data commons is:
HASS and Indigenous
10 -23
Apr
Social Sciences Research Infrastructure Co-Design Workshops
Go to eventabout Social Sciences Research Infrastructure Co-Design Workshops

As part of our Research Software Agenda for Australia, the ARDC is working with the research community to shape better research software in order to recognise it as a first-class output of research. This interview is the 11th in a series about research software engineers in Australia. Each month we talk to a leading research software engineer about their experiences and best-practice tips in creating, sustaining and improving software for research.
Continuing the series, we spoke with Cynthia Huang, who describes herself as a data scientist, economist and storyteller. Cynthia is currently pursuing a PhD at Monash University’s Department of Econometrics and Business Statistics and Department of Human Centred Computing with support from the Monash Data Futures Institute. She is also a host of the podcast The Random Sample, telling stories about maths, stats and data science.
My interest in coding grew after I finished my honours in Economics and started working as a Research Assistant at the University of Melbourne and eventually at SoDa Labs at Monash University. I worked on collecting and preparing data for several different projects, and as the datasets became larger and more varied, I improved my coding out of necessity.
For about 4 years, I worked with economists to turn all types of data into datasets ready for analysis. The data ranged from conventional survey data and official statistics to alternative sources like archival magazine scans and web-scraped text. Working across multiple projects, I started to recognise common workflows and challenges, which allowed me to help researchers produce higher-quality, more transparent and better-documented data. From there, it seemed natural to try and formalise these processes and learnings in the form of research software.
The overall aim of my PhD is to contribute concepts and tools to make data preparation more transparent, modular and reusable with a particular focus on data used by social scientists. One of the projects involves improving the preparation and merging of related datasets into a single integrated dataset.
The first part of this project is to propose a conceptual framework. This framework, called “crossmap”, formalises and describes the actions required to harmonise data between classifications, which can involve transforming variables by:
There are already many tools for performing each of these actions independently. However, disaggregation, which requires defining shares or proportions for the new groups, as well as combinations of all 3 actions is often implemented in highly customised and varied ways. This conceptual framework documents and validates the subjective choices in each of these actions as a workflow that is easily shared, modified and reused, even between different coding languages.
The second part is the software implementation of the conceptual framework – in this case the R package xmap – which will help researchers create, validate, visualise and use the crossmap.
Consider combining occupation statistics from Australia with other countries. Each country might have slightly different occupation categories depending on the local labour market. For any 2 countries, some categories might have one-to-one matches, whilst others might be a combination of one-to-many or many-to-one matching categories. Moreover, there’s often some subjectivity around which categories should match which.
With my proposed approach, the crossmap captures all of these decisions in a graph format that can be easily visualised (as seen in the figure below), allowing domain experts as well as team members who might not read code to design or verify the category mappings. The same object can be used to transform data, reducing the risk of coding mistakes affecting the final dataset.
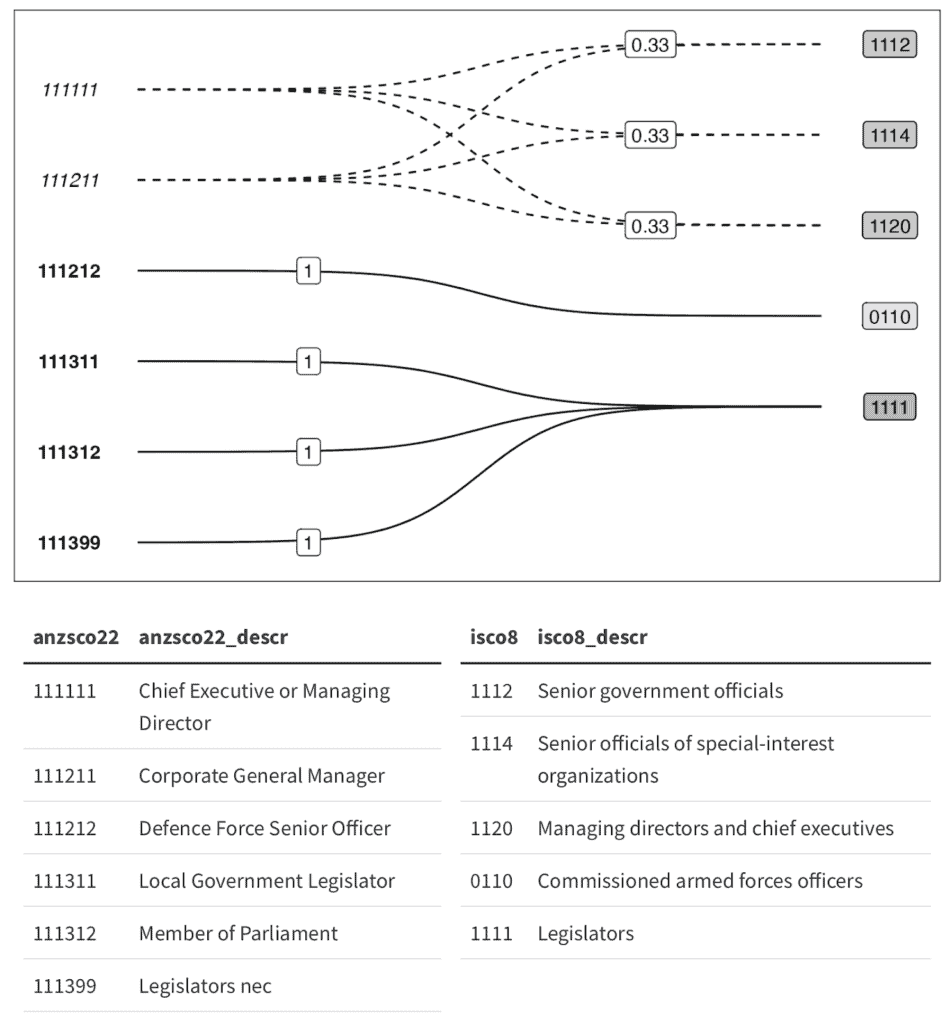
All in all, this project will make it easier for researchers to not only produce high-quality reproducible datasets, but also document, share and experiment with more complex data preparation decisions, such as category mappings and disaggregation shares.
Interactions with domain experts are vital in shaping the tools and software I am working on. The crossmap project incorporates feedback and ideas from many of the researchers I worked with. I’ve also been lucky to develop many of the ideas for this project with Associate Professor Laura Puzzello, a trade economist at Monash who funded my initial work on the software implementation and helped me understand the informal ‘rules’ for harmonising trade data, also known as concordance in the field. This helped me see beyond frictions in the coding process and consider also data quality control and transparency challenges when dataset preparation is split between multiple team members. It’s really helped me conceptualise and design the tool to have the combined perspectives of a practitioner and an RSE.
Social scientists are a very diverse group with a great variety of research interests, questions and methods. This diversity carries over into the types of data used. I think more than other disciplines, social scientists will tend to use whatever data they can get their hands on – images, text, surveys, administrative data – you name it and someone has probably tried to wrangle and analyse it. This makes designing and disseminating research software for them somewhat more challenging than it might be in other fields with more similar or standardised data sources and workflows. Unfortunately, different areas of social science also tend to use different terminology for the same things. Even the process of harmonising data has many names, including but not limited to ex-post harmonisation, crosswalking, concordance and recoding.
I often think about how I can help researchers find my software without knowing all the ways they might describe the data preparation task and formal transformation actions. However, I also want to challenge the idea that the types of data preparation and preprocessing that social scientists do are too complex or idiosyncratic to formalise into generalisable and flexible frameworks. Even if the data sources and preprocessing steps are highly varied, I think there are plenty of opportunities to create conceptual vocabulary and software tools that help prevent mistakes before they propagate through and impact downstream analysis.
I recommend everyone make use of coding drop-in hours. They’re a great way to meet other coders and get feedback about your research software ideas. At universities, there’s usually one run by research services, but there are other options too. At Monash, Data Fluency runs Friday drop-in sessions. Within my department, the NUMBATS research group also runs an internal bi-weekly ‘hacky hour’, where we code together and help each other with tricky R problems. If you’re not part of a university, and don’t know enough coders to start your own hacky hour, there’s also the rOpenSci co-working hours. I’ll be hosting the June session, and anyone is welcome to join!
I also learnt about the RSE Association of Australia and New Zealand (RSE AUNZ) mailing list last year after attending the 2022 RSE Asia Australia Unconference, and it became a community I relate with. If you’d like to be part of the growing community of research software engineers in Australia, become a member of the RSE-AUNZ – it’s free!
You can connect with Cynthia via Linkedin, Github, Twitter and Mastodon. She can talk to you about the crossmap project or research software and reproducibility in the social sciences.
Stay tuned for our next interview in the Shaping Research Software series, coming out in June.
Learn more about the ARDC’s Research Software Agenda for Australia.
The ARDC is funded through the National Collaborative Research Infrastructure Strategy (NCRIS) to support national digital research infrastructure for Australian researchers.

