
29 -31
Oct
2024 eResearch Australasia Conference
Go to partner eventabout 2024 eResearch Australasia Conference

Understanding the quality of a dataset is crucial for its reusability and for reproducing research. But what is ‘quality’ and how do we record it and make it accessible in a consistent way across datasets from disparate disciplines and domains?
The ARDC is calling on the Australian and New Zealand research community to join the Data Quality Interest Group and help define a global best practice for describing and publishing data quality information.
How often do you hear someone say: “We can’t use that dataset; it’s poor quality”? Or: “I don’t trust that repository; their datasets are full of errors”?
Though the reliability of some datasets may be perceived as questionable, the broader and more pressing problems are that there is no standard measure of dataset quality and no standard way of describing dataset quality information.
“For some repositories, there is no quality information in their metadata, so users have to download a dataset and look at it themselves to judge,” says ARDC’s Dr Mingfang Wu. “Some repositories do provide information about quality, but it doesn’t line up with any standard other than their own inhouse measures.”
What we urgently need, says Mingfang, is a community-agreed best practice, preferably international, for documenting dataset quality information.
Mingfang co-chairs the ARDC-supported Australia–New Zealand Data Quality Interest Group, alongside Dr Ivana Ivánová (Curtin University), Irina Bastrakova (Geoscience Australia), Dr Lesley Wyborn (National Computational Infrastructure (NCI)) and Miles Nicholls (Atlas of Living Australia). The importance of providing dataset quality information has been increasingly recognised, she says, and membership has grown to more than 90 since the group was established about two years ago.
“People come to see if anyone else in the room has the same problem, or if they have a solution to it,” says Mingfang. Being well connected to international bodies, the co-chairs are able to bring the latest developments to the Australian and New Zealand community.
“In the last 5 or 6 years we have focused on making datasets FAIR (Findable, Accessible, Interoperable, Reusable),” says Mingfang, “but unless information about a dataset’s quality is included, it may be hard to reuse it.”
Imagine you need to merge several datasets, or you’re planning to use a dataset for reasons not intended by its creator. In these instances, information about the quality of the dataset is critical, particularly if you’re planning to use AI or machine learning.
Lesley puts it simply: “If you don’t know the quality of a dataset, you can’t be sure it is fit for your purpose.”
Thanks to its international connections, the Australia–New Zealand Data Quality Interest Group is now part of a landmark international collaboration to define dataset quality in the Earth sciences — an interdisciplinary effort which includes, among many others, the Earth Science Information Partnership (ESIP) and the Barcelona Supercomputer Centre.
The collaboration’s 22 interdisciplinary domain experts from 7 countries (USA, Spain, Australia, New Zealand, Germany, United Kingdom, France) include data producers, data stewards, service providers, data publishers and data users.
In May this year, in a paper published in Data Science Journal, the collaborators called for global access to and harmonisation of quality information of individual Earth science datasets. In it, they describe the 4 aspects of dataset quality, based around the dataset life cycle (Figure 1).
By October, after extensive community review, they had released international community guidelines for sharing and reusing quality information for Earth science datasets.
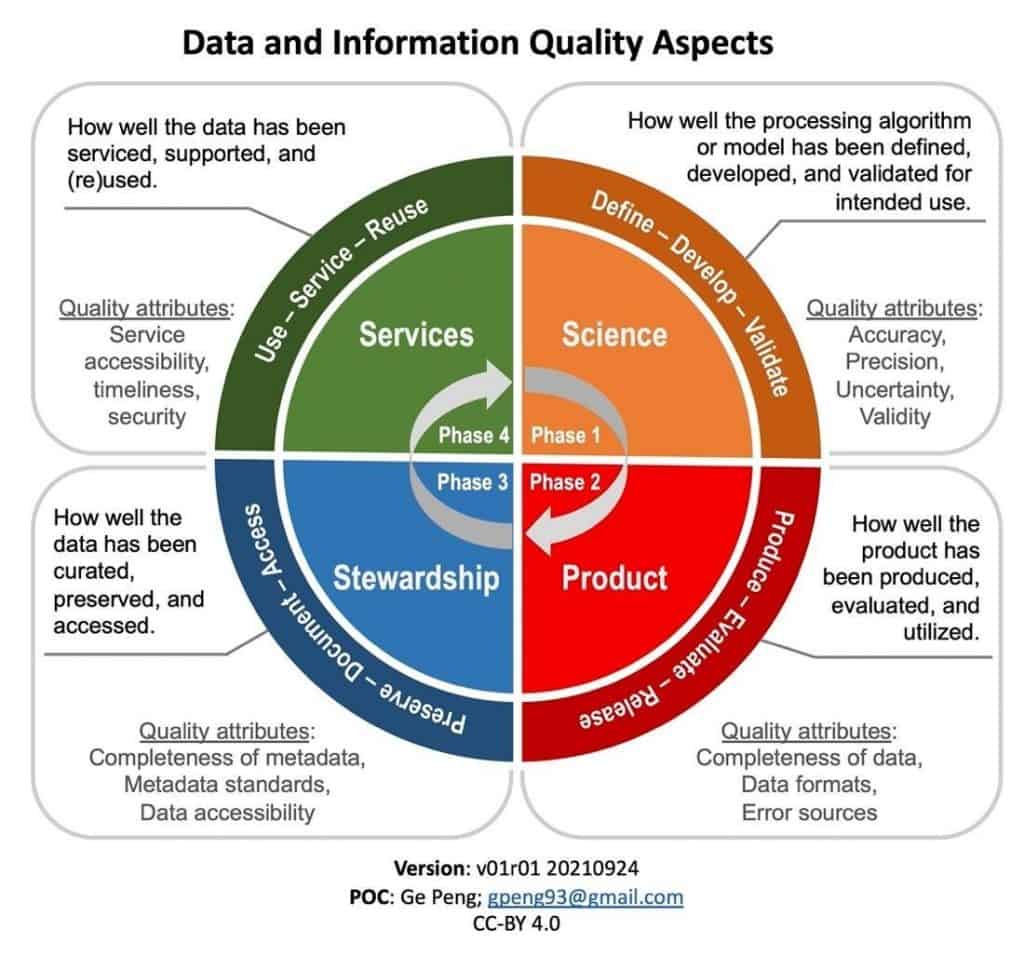
“As you pass through the phases — science, product, stewardship and services — not only do the quality attributes change, so too do the people and skills required to document quality,” adds Peng.
“Also, the quality information needs to be recorded when the data is being collected and processed. For some datasets, it could be done retrospectively, but for many this is difficult because by then you may have lost the contextual information of the data.”
Both the dataset and any information on quality assurance/control of the data need to be FAIR and preferably machine readable, says Ming. If the quality information is machine readable, the quality of the dataset and its metadata could be assessed automatically.
Extending the Earth sciences guidelines to cater for the social sciences, astronomy, biodiversity, and genomics is in the Data Quality Interest Group’s sights, and is likely to be facilitated through the international Research Data Alliance (RDA). At a Birds of a Feather session held at this month’s RDA plenary, many participants said they were eagerly awaiting the setting up of a working group to recommend how dataset quality information could be represented and communicated.
To make sure that the needs of Australia and New Zealand are fully represented, and that ideas and current practices are considered, we are calling for people to join the Data Quality Interest Group.
“We want people to not just join, but contribute at all levels,” says Dr Ivana Ivánová from Curtin University. “We are now collecting use cases of how people are measuring, defining and assessing the quality of their datasets, and how they are attaching these quality measures to their datasets, so that the guidelines are in line with the user communities and their applications.”
The best practices may be right under our nose. After all, Lesley only discovered the best practice quality documents of IMOS (Australia’s Integrated Marine Observing System), an exemplar in documenting quality for instrument data, when the US-based ESIP drew her attention to them.
Let’s not leave it to chance — join the Data Quality Interest Group now.
The ARDC is funded through the National Collaborative Research Infrastructure Strategy (NCRIS) to support national digital research infrastructure for Australian researchers.


